

超越摩尔-存算一体架构探究
一、超越摩尔,人工智能时代需要新的芯片架构
目前市面存在的基于CPU、GPU等的计算系统都是基于冯诺依曼结构,其运算与存储部件是分离的,进行计算时,计算单元需要将数据从存储单元中提取出来,处理完成后再写回存储单元,这种结构导致了密集数据计算时需要在存储部件与计算部件传输大量数据,这就造成计算速度受到数据传输带宽限制,同时引起功耗增加,限制了计算系统的性能提升。另一方面,现有的CPU、GPU等处理器都是使用数字电路实现计算功能,因而需要大量的计算资源,这也限制了可以达到的计算并行度以及计算速度。
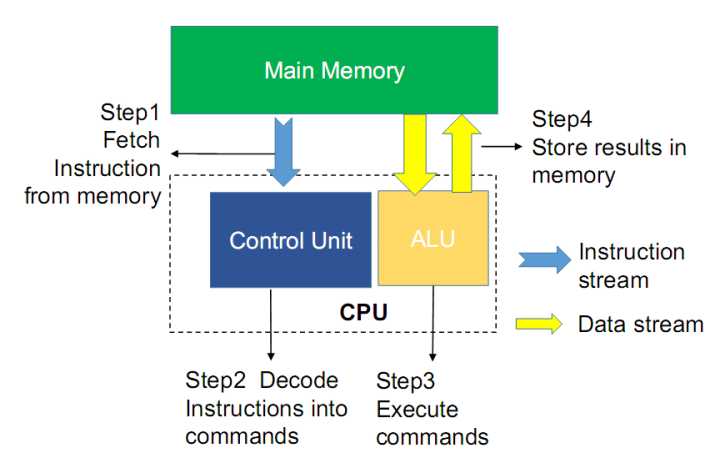
图1 冯诺依曼架构图
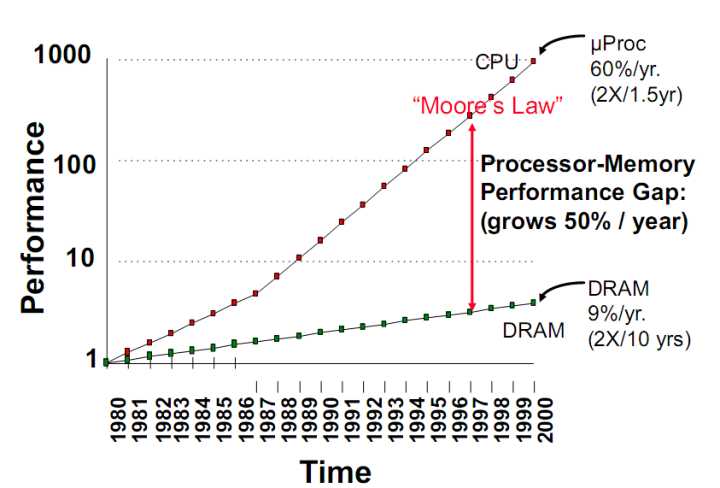
图2 存储墙剪刀叉
造成“存储墙”的根本原因是存储与计算部件在物理空间上的分离。从图2中可以看出,从 1980年到 2000年,两者的速度失配以每年 50%的速率增加。为此,工业界和学术界开始寻找弱化或消除“存储墙”问题的方法,开始考虑从聚焦计算的冯诺依曼体系结构转向聚焦存储的“计算型存储/存算一体/存内计算”。
今年年初阿里达摩院发布了2020年十大科技趋势,它认为存算一体是突破AI算力瓶颈的关键技术。因为利用存算一体技术,设备性能不仅能够得到提升,其成本也能够大幅降低。
冯诺伊曼架构的存储和计算分离,已经不适合数据驱动的人工智能应用需求。频繁的数据搬运导致的算力瓶颈以及功耗瓶颈已经成为对更先进算法探索的限制因素。类似于脑神经结构的存内计算架构将数据存储单元和计算单元融合为一体,能显著减少数据搬运,极大提高计算并行度和能效。计算存储一体化在硬件架构方面的革新,将突破AI算力瓶颈。
二、计算型存储/存算一体研究现状
随着3D堆叠技术的发展,以及新型非易失性存储器器件的日益成熟,面向人工智能算法的大数据应用需求,计算型存储/存算一体逐渐受到了工业界和学术界的关注。
目前,已经有很多厂商和研究机构开始进入计算型存储/存算一体领域,例如,INTEL、IMB和三星等厂商纷纷推出实验型架构,一些研究机构也开始基于新器件新材料提前展开研究工作。
根据存储器件的存储易失性分类,计算型存储/存算一体的实现主要聚焦在两类存储上:
1)基于易失性的SRAM或DRAM构建;
2)基于非易失性的相变存储器PCM、阻变存储器/忆阻器ReRAM、浮栅器件和闪存FLASH构建。
2.1 基于易失性存储SRAM和DRAM的计算型存储/存内计算
易失性存储器SRAM和DRAM工艺成熟,是目前商业化的主要存储器产品。因此,很多的厂商和研究机构开始基于SRAM和DRAM展开存内计算的研究。但是,目前这种计算型存储/存内计算存在一定的问题:
1)由于目前的存内计算还处于实验阶段,存储器厂商对工艺和制程的约束,大多数的研究都是在SRAM和DRAM的灵敏放大器端做工作,无法深入到存储单元实现存储和计算的完全耦合;
2)目前的计算型存储/存内计算基本上智能支持逻辑操作和无进位的计算,对于存储单元间的信息交互还额外需要计算逻辑和控制逻辑的支持。
2.2 基于非易失性存储器的新型计算型存储/存算一体
非易失性存储器在最近十几年得到了飞速的发展,包括自旋矩磁存储器STTRAM,相变存储器PCM、阻变存储器RRAM等。工业界和商业界已经发布了众多容量达到Gb量级的产品,Micon在2010年发布了45nm工艺的1Gb的PCM,三星2012年推出了20nm工艺的8Gb PCM,随后在2015年Micron联合三星一起推出了27nm的16Gb conductive bridge (CBRAM, 一种特殊的RRAM)。 同年, Micron和Intel共同发布了128Gb 3D XPoint 技术。2013年,Toshiba联合Sandisk发布了24nm工艺的32Gb RRAM。
随着非易失性存储器产品的不断成熟,容量不断增大,研究者开始考虑基于非易失性存储器构建存储系统的可能性。同时,由于非易失性存储器对计算和存储的天然融合性,很多的研究和产品开始朝着基于非异失性存储器的计算型存储/存算一体发展。
1)相变存储器相变存储(PCM)是基于硫属化物玻璃材料,能在施加合适电流时将介质从晶态变为非晶态并再变回晶态,基于材料所表现出来的导电性差异来存储数据。
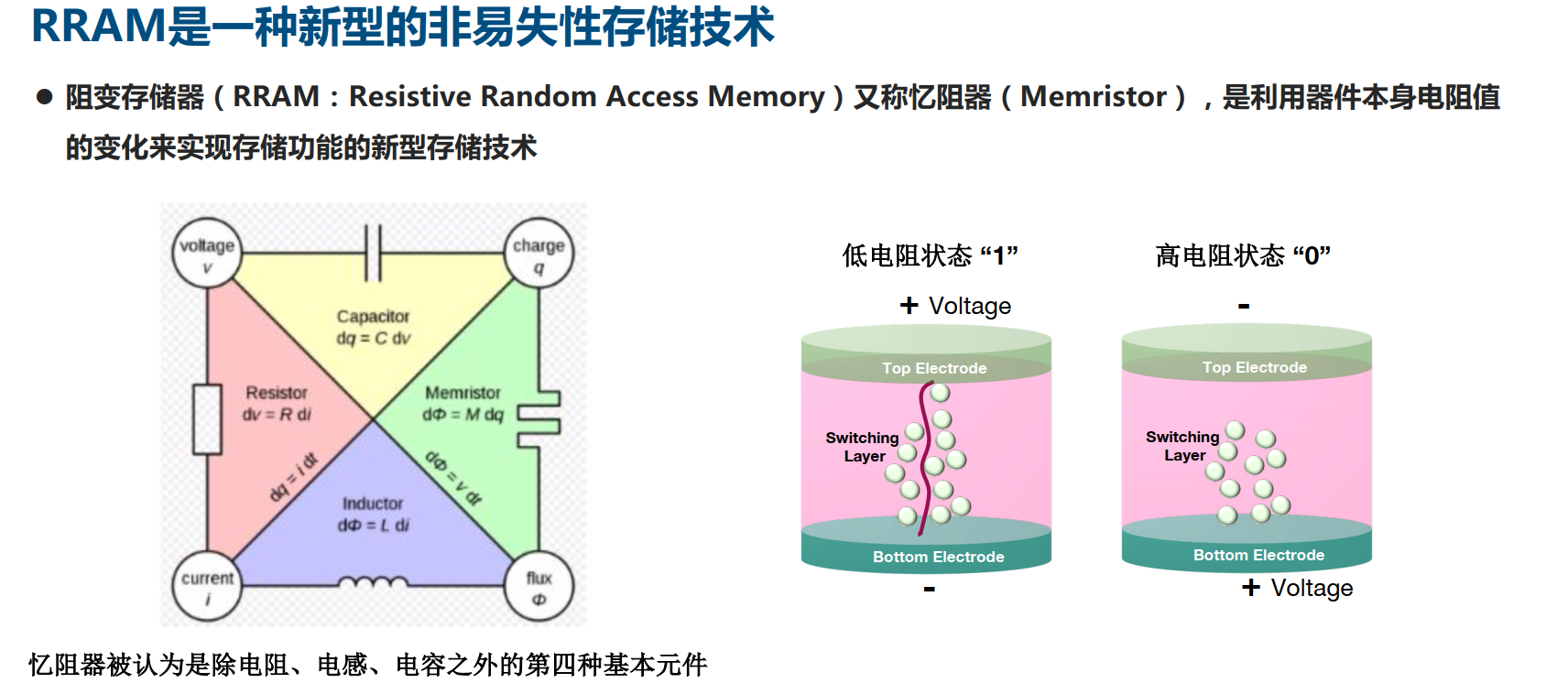
2)基于阻变存储器ReRAM/忆阻器的计算型存储/存算一体忆阻器最早由美国柏克莱大学的蔡少棠于1971年提出。忆阻器是一种有记忆功能的非线性电阻,其电阻会随着流过的电路而改变。在断电之后,即使电流停止了,电阻值仍然会保持下去,直到反向电流通过,它才会返回原状。所以,通过控制电流变化可以改变其阻值,例如将高阻值定义为1,低阻值定义为0,从而实现数据存储功能。2010年惠普实验室再次宣布忆阻器具有布尔逻辑运算功能,这意味着计算和存储两大功能可以再忆阻器上合为一体,可能从根本上颠覆传统冯诺依曼架构奠定了器件基础。
3)基于浮栅器件/Flash的计算型存储/存算一体
浮栅器件工艺成熟,编程时间10-1000ns,可编程次数10^5,存储阵列大,实现量产运算精度高,密度大,效率高,成本低。适合深度学习和人工智能应用。
目前基于闪存的计算型存储/存算一体的是一家存算一体芯片设计公司,知存科技。闪存的存储单元为三端器件,知存科技利用这一特点,基于NOR Flash构建了存算一体芯片。把乘数直接存入存储单元内,再把数值输入到闪存的阵列之中。每个单元都进行乘法,最后通过一条路径求和,就可以达到存算一体的效果。乘法计算的方式是通过类似模拟电路的电流镜方式。输入电流转换成电压耦合到Flash晶体管的控制栅上,Flash晶体管的输出电流等于输入电流和存储的权重相乘。加法的计算方式类似于并联电路电流求和。具体的实现细节并未被披露出来,目前还未知其内部的设计。根据宣称,2016 和 2017年知存科技的 CTO 曾做出了多个样品,最高峰值运算效率为40TOPS/W,平均值为 10TOPS/W。
三、结语
虽然存算一体技术方向广受认可,英特尔、ARM、微软等公司也均参与到该技术方向的投资,也有知存科技、闪亿半导体、新亿科技、智芯微电子等多家公司给出了可行的存算一体解决方案,但有一个不争的事实是,没有一家公司的存算一体技术解决方案受到广泛的市场认可。
随着AI需求的演进,可以相信的是,产业界会对芯片内部相应优化,通过调整设计架构,使其更好地支持现有网络支持,可配置性更多,对新型网络效率更高,整体芯片面积也变得更小。
存算一体毕竟是一个创新芯片架构,缺乏成熟的EDA工具、测试工具和应用层适配软件,量产步骤还够不成熟。不同于传统芯片直接将量产步骤交由晶圆厂来完成,存算一体芯片的量产步骤需要芯片设计公司和晶圆厂一起来探索和建立。对于致力于推进存算一体的创业AI芯片公司,如何找准芯片应用行业方向,需求落地场景,如何融入产业需求,如何推进量产是接下来需要面对和解决的核心难题。
